



2026 年,AI 將主導網路安全攻防,自動化攻擊將成常態,供應鏈、雲端環境成為主要目標。趨勢科技預測,企業需強化 AI 防護,著重漏洞自動搜尋、模擬內部員工行為的攻擊。傳統雲端錯誤設定、API 暴露等問題將被 AI 放大。企業應將安全策略與 AI 工具同步演進,建立智慧化、差異化的 AI 安全策略,應對快速變動的風險…
標籤: AI 信息可靠性评估
-
歐盟築高牆:5G供應鏈大洗牌,科技自主與地緣政治角力全面開展
“`html 歐盟強化5G網路安全法規:逐步淘汰高風險電信供應商的地緣政治影響 歐盟近期公布網路安全法修正案草案,計畫在關鍵產業逐步淘汰來…

-
鐵道安全大考驗:從事故反思到月台門可行性,如何打造更安全的乘車環境?
軌道安全防護系統:事故反思與月台門建置技術可行性分析 近年來,鐵道行車安全事故層出不窮,引發了社會的廣泛關注。為了加強鐵道行車安全,各地政府…
-
AI推理效能大躍進:Token倉架構突破記憶體瓶頸的新方案
本文探討了基於 Token 倉架構的 AI 推理記憶體瓶頸解決方案。該架構通過優化 AI 模型參數與中間結果的存儲,減少記憶體訪問延遲和能耗…
-
xAI Grok 圖像生成爭議:加州檢察長介入調查,全球監管機構高度關注
xAI 天機器人 Grok 生成未成年性影像事件引發全球關注 近日,Elon Musk 下的 xAI 天機器人 Grok 因生成未成年性影像…

-
阿根廷海域中國魷魚漁隊:生態警報、安全隱憂與權益爭議深度解析
本報告分析了中國遠洋漁船隊在阿根廷海域的活動,指出其涉嫌非法捕魚,包括捕殺受保護物種和破壞海洋生態環境。報告強調,過度捕撈已對當地漁業資源和…
-
醫療資料安全大升級!衛福部主權雲八大方,打造堅不可摧的醫療雲端防護網
衛福部主權雲方:強化醫療雲端資料安全與採購標準 近年來,醫療機構接連成為客攻擊目標,讓醫療資料的安全性成為了一個重的問題。為了應對這個挑戰,…
-
**AI監控陷阱:Flock攝像頭漏洞大揭秘,公共空間隱私岌岌可危**
研究揭露,Flock Safety 的 AI 監控攝影機存在配置漏洞,導致車牌識別、人臉偵測等敏感影像資料外洩,管理介面和 AI 模型也未受…

-
>個人AI代理的信任問題:現狀、挑戰與可信度提升策略
個人AI代理的信任問題:現狀、挑戰與可信度提升策略 隨著AI代理技術的快速發展,人工智慧代理人已經滲透到各行各業,改變著我們的工作、消費和互…

-
生成式AI安全治理:美國多州檢察長要求強化稽核與事故通報機制
美國 42 州總檢察長聯署要求 13 家 AI 供應商於 2026 年前建立第三方稽核、事故公開紀錄及即時通報機制,以應對「迎合式」及「妄想…

-
LLM 的數學阿基里斯腱:詳解 AMO-Bench 評測與 AI 推理優化策略
LongCat AMO-Bench 基準測試旨在評估 LLM 在高中數學題目的推理能力。基準包含一萬道涵蓋代數、幾何、微積分的題目,並採用「…

Chainlit AI框架重磅警訊:敏感資料外洩與系統接管風險浮現!
Chainlit AI框架漏洞:資料取與SSRF風險分析 近期,開源AI框架Chainlit被發現存在兩個易於利用的漏洞,分別是CVE-2026-22218(任意文件讀取)和CVE-2026-22219(服器端請求造…


韋伯望遠鏡:上帝之眼下的恆星終焉與新元素誕生
韋伯太空望遠鏡對螺旋星雲的觀測,揭示了恆星死亡後物質循環回宇宙的細節。紅外線觀測穿透塵埃,呈現白矮星釋放物質撞擊周圍氣體塵埃外殼的過程,並發現複雜分子形成。不同顏色代表不同溫度,揭示新一代恆星和行星的原材料。此研究對於理解恆星生命週期,宇宙演化具有重要意義。同時,在獵戶座大星雲中也發現了大量水分子。…

告別高昂代碼 AI 費用!Goose 登場:開源、離線,本地端也能玩轉 AI 程式碼助手
Goose 是一款開源、離線的 AI 程式碼代理人,旨在挑戰 Claude Code 的高費用。它提供代碼自動完成、調試、導航等功能,與 Claude Code 類似。Goose 的主要優勢在於其開源性及離線使用特性,允許開發者在本地環境中使用,無需雲端服務費用,並可根據需求修改和擴展代碼。這為開發者提供了一個無需高額…
歐盟築高牆:5G供應鏈大洗牌,科技自主與地緣政治角力全面開展
“`html 歐盟強化5G網路安全法規:逐步淘汰高風險電信供應商的地緣政治影響 歐盟近期公布網路安全法修正案草案,計畫在關鍵產業逐步淘汰來自高風險供應商的零組件與設備,此舉預料將對華為及其他中國科技企業產生深遠影響…
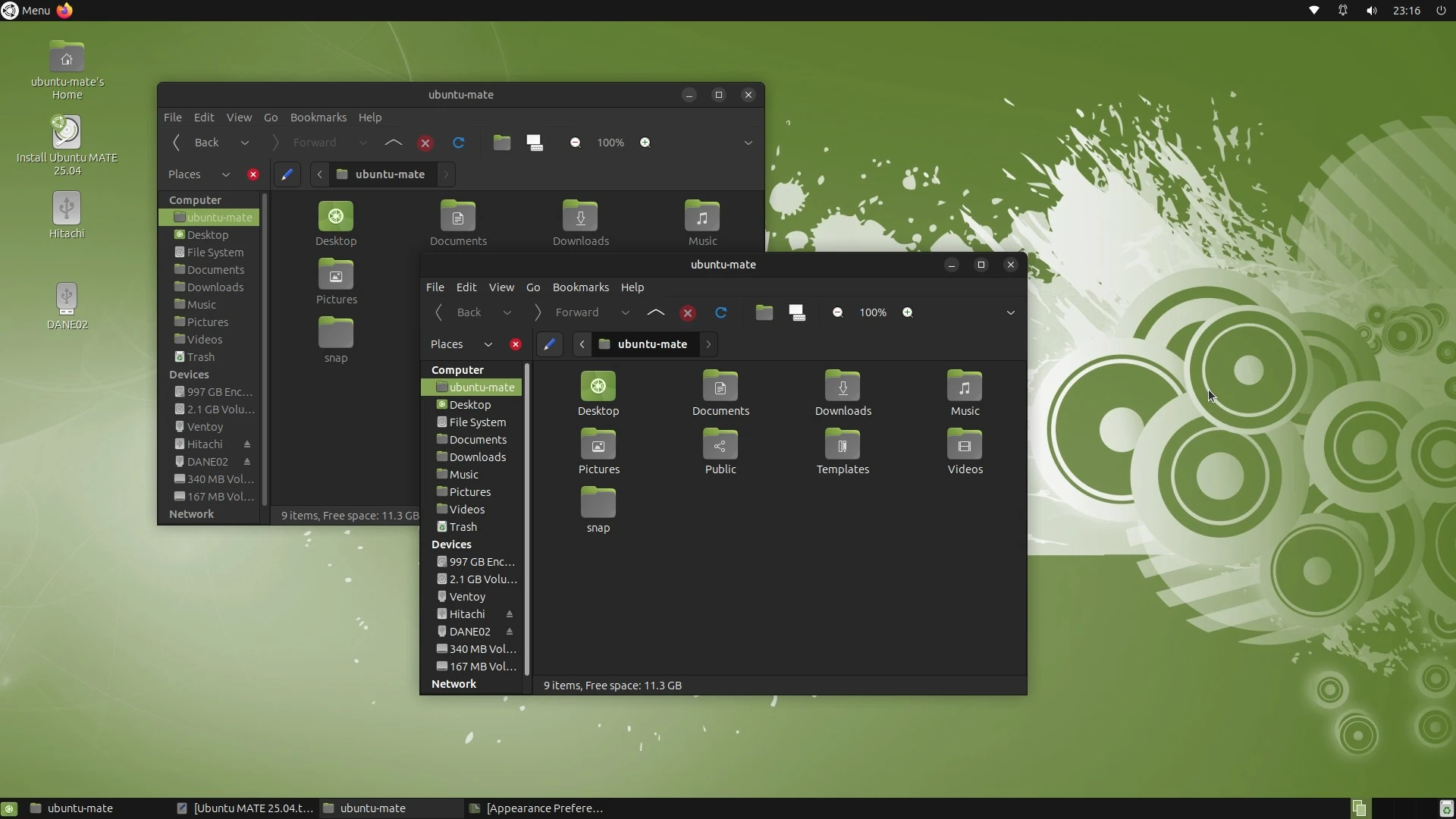
Ubuntu 26.04 Live USB:Domino 應用與持久模式,輕鬆體驗新系統!
本文介紹了配置 Ubuntu 26.04 Live USB 的方法,包括下載 ISO 檔案、使用 Ventoy 等工具燒錄 USB、以及設定 BIOS 開機順序。文章進一步探討了在 Live USB 環境下實測 Domino 應用伺服器的可行性,涵蓋安裝、配置環境變數、啟動服務器和測試功能等步驟。最後,文章提及了持久模…
AI自主客戶服務
若有任何需求可以直接詢問專業AI客服
