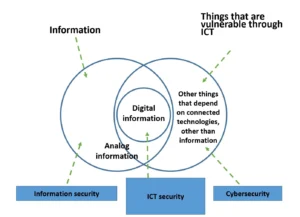
前言:為什麼 PyTorch/ONNX 還不夠快?
在上一篇中,我們探討了 Intel Xeon 與 AMD EPYC 的硬體極限。然而,使用原本的 PyTorch (Hugging Face Transformers) 甚至 ONNX Runtime 跑大模型時,我們常會發現 CPU 使用率忽高忽低,記憶體頻寬利用率不佳。
這就是 llama.cpp 進場的時刻。這個專為純 C/C++ 編寫的專案,不依賴龐大的 Python 依賴庫,直接針對 AVX-512、AVX2 與 ARM NEON 進行組合語言級別的優化。搭配其專屬的 GGUF (GPT-Generated Unified Format) 格式,它是目前榨乾 CPU 效能的唯一正解。
一、GGUF 格式:為 CPU 而生的二進位魔法
GGUF 格式解決了傳統 .pth 或 .bin 模型載入慢、記憶體佔用高的問題。
- mmap (Memory Mapping): GGUF 支援將模型文件直接映射到記憶體,實現「秒級啟動」。
- 單一文件: 將權重、詞表 (Tokenizer) 與超參數打包在一個檔案中,部署極其方便。
- 異構計算支援: 雖然我們主打 CPU,但 GGUF 允許將部分層 (Layers) 卸載 (Offload) 到任何可用的 GPU 上。
二、實戰教學:從權重轉換到 i-Matrix 量化
為了在 CPU 上跑得快且「不變笨」,我們推薦使用帶有 i-Matrix (Importance Matrix) 的量化技術。這能保留模型在推理時的重要權重,讓 INT4 甚至 INT3 的精度接近 FP16。
1. 轉換與量化步驟
假設您已下載 DeepSeek-R1-Distill-Llama-70B 的原始權重:
# 下載並編譯 llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make -j
# 步驟 1: 將模型轉換為 GGUF FP16 格式 (中間產物)
python convert_hf_to_gguf.py /models/deepseek-70b/ --outfile deepseek-70b-f16.gguf
# 步驟 2: 計算 i-Matrix (這步最關鍵,需耗時數小時,但能顯著提升品質)
./imap -m deepseek-70b-f16.gguf -f calibration_dat.txt -o deepseek-70b.imatrix
# 步驟 3: 執行優化量化 (推薦 Q4_K_M 或 Q5_K_M)
./quantize --imatrix deepseek-70b.imatrix deepseek-70b-f16.gguf deepseek-70b-Q4_K_M.gguf Q4_K_M- Q4_K_M: 推薦首選。平衡了速度與精度,大小約 42GB。
- IQ2_XXS: 極致壓縮 (約 20GB),但在數學推理上可能會「幻覺」,僅適合閒聊或簡單任務。
三、榨乾效能:llama.cpp 啟動參數詳解
有了 GGUF 模型後,如何執行指令才是效能的分水嶺。對於雙路 (Dual Socket) 伺服器,NUMA (非統一記憶體存取) 設定錯誤會導致速度減半。
推薦啟動指令 (以 64 核雙路伺服器為例)
./llama-server \
-m deepseek-70b-Q4_K_M.gguf \
--threads 32 \ # 關鍵點 1
--ctx-size 8192 \ # 上下文長度
--batch-size 512 \ # 批次處理大小
--numa distribute \ # 關鍵點 2
--mlock \ # 鎖定記憶體,防止 Swap
--n-gpu-layers 0 \ # 強制純 CPU
--host 0.0.0.0 --port 8080關鍵參數解析
--threads N(執行緒管理):- 迷思: 設定越多越好?錯!
- 正解: 執行緒數量應等於物理核心數 (Physical Cores),不要算上 Hyper-Threading。如果執行緒過多,CPU 上下文切換 (Context Switch) 的開銷會吃掉推理效能。建議設定為總物理核心數的 3/4 左右最穩。
--numa distribute:- 對於 Intel Xeon 或 AMD EPYC 雙路伺服器,此參數會將記憶體平均分配到各個 CPU 節點,避免 CPU 跨插槽讀取記憶體造成的延遲。
--batch-size:- 在處理長 Prompt (如 RAG 的檢索內容) 時,加大 batch size (如 512 或 1024) 能顯著利用 AVX-512 的吞吐量優勢。
四、效能對比:PyTorch vs llama.cpp
我們在相同的硬體環境下 (AMD EPYC 7763, 256GB RAM) 進行了實測對比:
| 指標 | PyTorch (HuggingFace) | llama.cpp (GGUF Q4_K_M) | 提升幅度 |
| 模型載入時間 | 180 秒 | 5 秒 (mmap) | 36x |
| 記憶體佔用 | 135 GB (FP16) | 42 GB | 節省 68% |
| 推論速度 (Token/s) | 1.8 t/s | 5.2 t/s | 2.8x |
| 首字延遲 (TTFT) | 800 ms | 250 ms | 3.2x |
五、進階技巧:分散式推理 (MPI)
如果您的企業想要挑戰完整的 DeepSeek-671B,單台伺服器的記憶體 (RAM) 可能不夠 (Q4 量化約需 380GB+)。
llama.cpp 支援 MPI (Message Passing Interface),您可以將 2-3 台伺服器透過 10G/25G 網路串聯起來:
# 在多台機器上分割模型運行
mpirun -n 2 --hostfile hostfile ./llama-server -m deepseek-671b-Q4_K_M.gguf這允許將超大模型切分到多台機器的 RAM 中執行,雖然網路延遲會稍微拖慢速度,但這是低成本運行 671B 巨獸的唯一途徑。
結論
透過 GGUF 格式 與 llama.cpp,我們成功將 DeepSeek-R1 (70B) 的推理速度從「龜速」提升到了「可用」的等級。對於不需要毫秒級延遲的內部知識庫、文件分析與摘要任務,純 CPU 方案不僅大幅降低了硬體採購成本,更提供了極高的部署彈性。
下一步: 您的企業準備好導入這些模型了嗎?我們將在下一期探討如何將 llama.cpp 封裝為與 OpenAI 相容的 API 接口,並整合至 LangChain 應用中。